このモードは、データセットが計算ノードの nblocks ブロックに分割されていると仮定します。
アルゴリズムのパラメーター
分散処理モードの QR 分解のパラメーターは次のとおりです。
パラメーター |
デフォルト値 |
説明 |
|
|---|---|---|---|
computeStep |
適用不可 |
アルゴリズムを初期化するために必要なパラメーターです。次のいずれか。
|
|
algorithmFPType |
double |
アルゴリズムが中間計算に使用する浮動小数点の型。float または double を指定できます。 |
|
method |
defaultDense |
パフォーマンス指向の計算メソッド。アルゴリズムでサポートされている唯一のメソッドです。 |
|
3 ステップの計算スキーマを使用して QR 分解を計算します。
ステップ 1 - ローカルノード
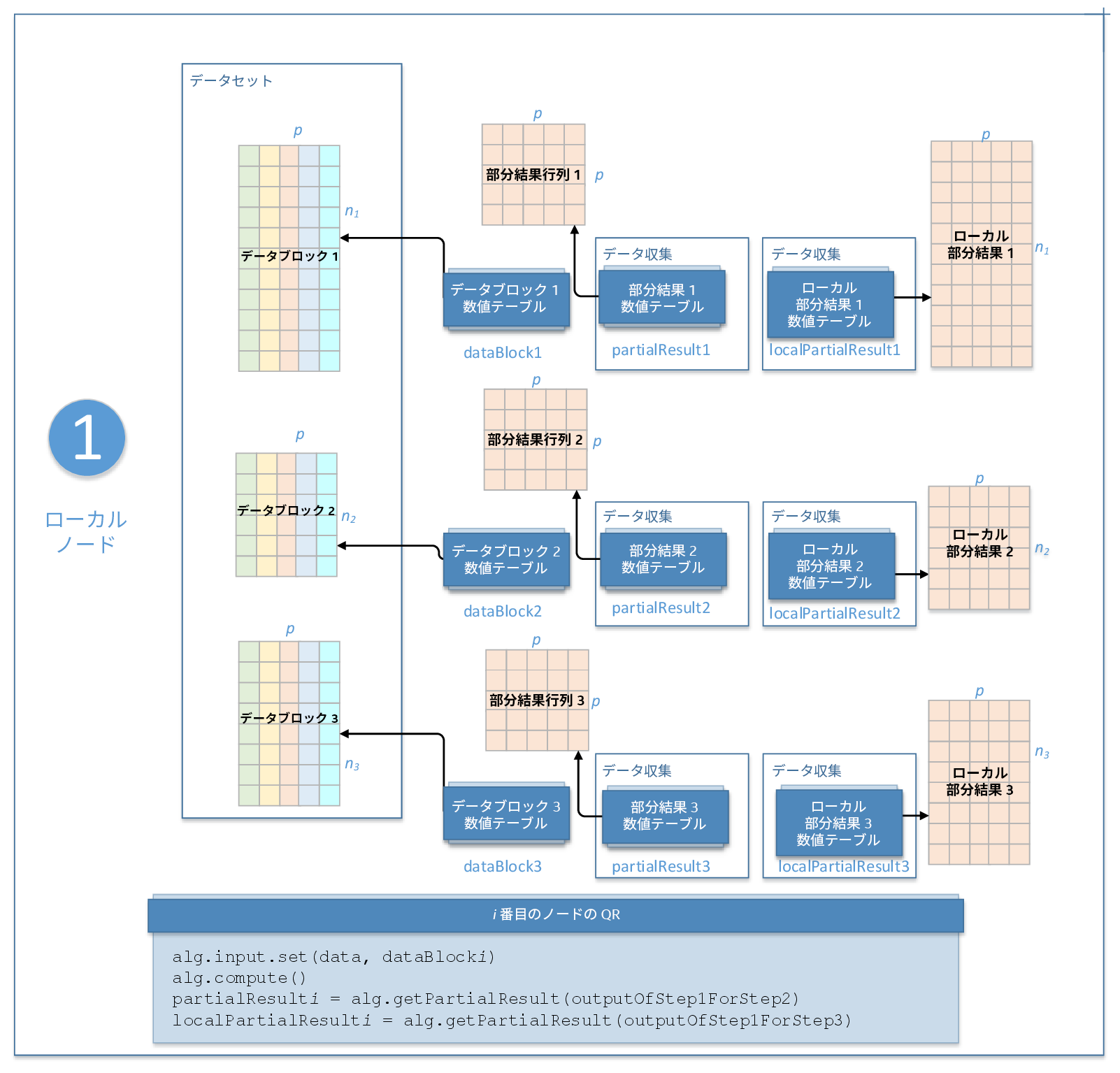
このステップの QR 分解の入力は次のとおりです。入力 ID をパラメーターとして、アルゴリズムの入力を提供するメソッドに渡します。詳細は、「アルゴリズム」を参照してください。
入力 ID |
入力 |
|
|---|---|---|
data |
ローカルノードの i 番目のデータブロックを表す ni x p 数値テーブルのポインター。各データブロックは十分なサイズ (ni > p) が必要なことに注意してください。入力は、NumericTable の派生クラスのオブジェクトです。 |
|
このステップで、QR 分解は次の結果を計算します。結果 ID をパラメーターとして、アルゴリズムの結果にアクセスするメソッドに渡します。詳細は、「アルゴリズム」を参照してください。
結果 ID |
結果 |
|
|---|---|---|
outputOfStep1ForStep2 |
ステップ 2 のマスターノードに転送する部分結果を含む数値テーブルのコレクション。デフォルトでは、これらのテーブルは HomogenNumericTable クラスのオブジェクトですが、(PackedSymmetricMatrix クラス、CSRNumericTable クラス、および lowerPackedTriangularMatrix レイアウトの PackedTriangularMatrix クラスを除く) NumericTable の派生クラスのオブジェクトとして定義できます。 |
|
outputOfStep1ForStep3 |
ステップ 3 のローカルノードで保持する部分結果を含む数値テーブルのコレクション。デフォルトでは、これらのテーブルは HomogenNumericTable クラスのオブジェクトですが、(PackedSymmetricMatrix、PackedTriangularMatrix、および CSRNumericTable を除く) NumericTable の派生クラスのオブジェクトとして定義できます。 |
|
ステップ 2 - マスターノード
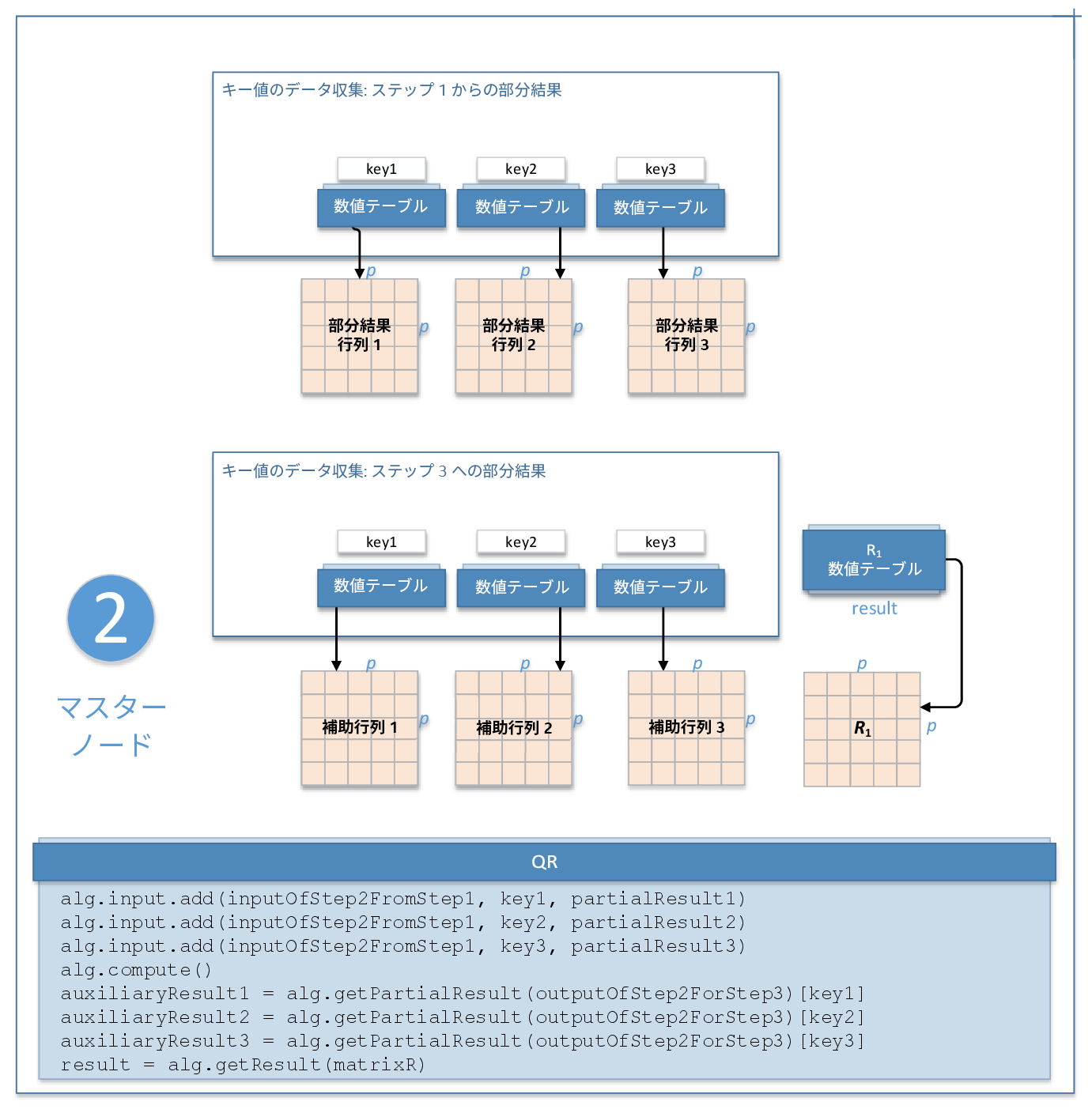
このステップの QR 分解の各ローカルノードからの入力は次のとおりです。入力 ID をパラメーターとして、アルゴリズムの入力を提供するメソッドに渡します。詳細は、「アルゴリズム」を参照してください。
入力 ID |
入力 |
|
|---|---|---|
inputOfStep2FromStep1 |
ステップ 1 でローカルノードで計算された結果 (outputOfStep1ForStep2) を含むコレクション。(PackedSymmetricMatrix クラスおよび lowerPackedTriangularMatrix レイアウトの PackedTriangularMatrix クラスを除く) NumericTable の派生クラスのオブジェクトをコレクションに含めることができます。 |
|
key |
キー、型 int の数。キーを使用すると、ステップ 1 (inputOfStep2FromStep1) の部分結果の順序を追跡できるため、ステップ 2 (outputOfStep2ForStep3) で計算された部分結果を全く同じ順序でローカルノードに戻すことができます。 |
|
このステップで、QR 分解は次の結果を計算します。結果 ID をパラメーターとして、アルゴリズムの結果にアクセスするメソッドに渡します。詳細は、「アルゴリズム」を参照してください。
結果 ID |
結果 |
|
|---|---|---|
outputOfStep2ForStep3 |
Q1 を計算するためにローカルロードに分割する数値テーブルを含むコレクション。デフォルトでは、これらのテーブルは HomogenNumericTable クラスのオブジェクトですが、(PackedSymmetricMatrix クラス、CSRNumericTable クラス、および lowerPackedTriangularMatrix レイアウトの PackedTriangularMatrix クラスを除く) NumericTable の派生クラスのオブジェクトとして定義できます。 |
|
matrixR |
n x p 上三角行列 R1 を含む数値テーブルのポインター。デフォルトでは、この結果は HomogenNumericTable クラスのオブジェクトですが、(PackedSymmetricMatrix クラス、CSRNumericTable クラス、および lowerPackedTriangularMatrix レイアウトの PackedTriangularMatrix クラスを除く) NumericTable の派生クラスのオブジェクトとして定義できます。 |
|
ステップ 3 - ローカルノード
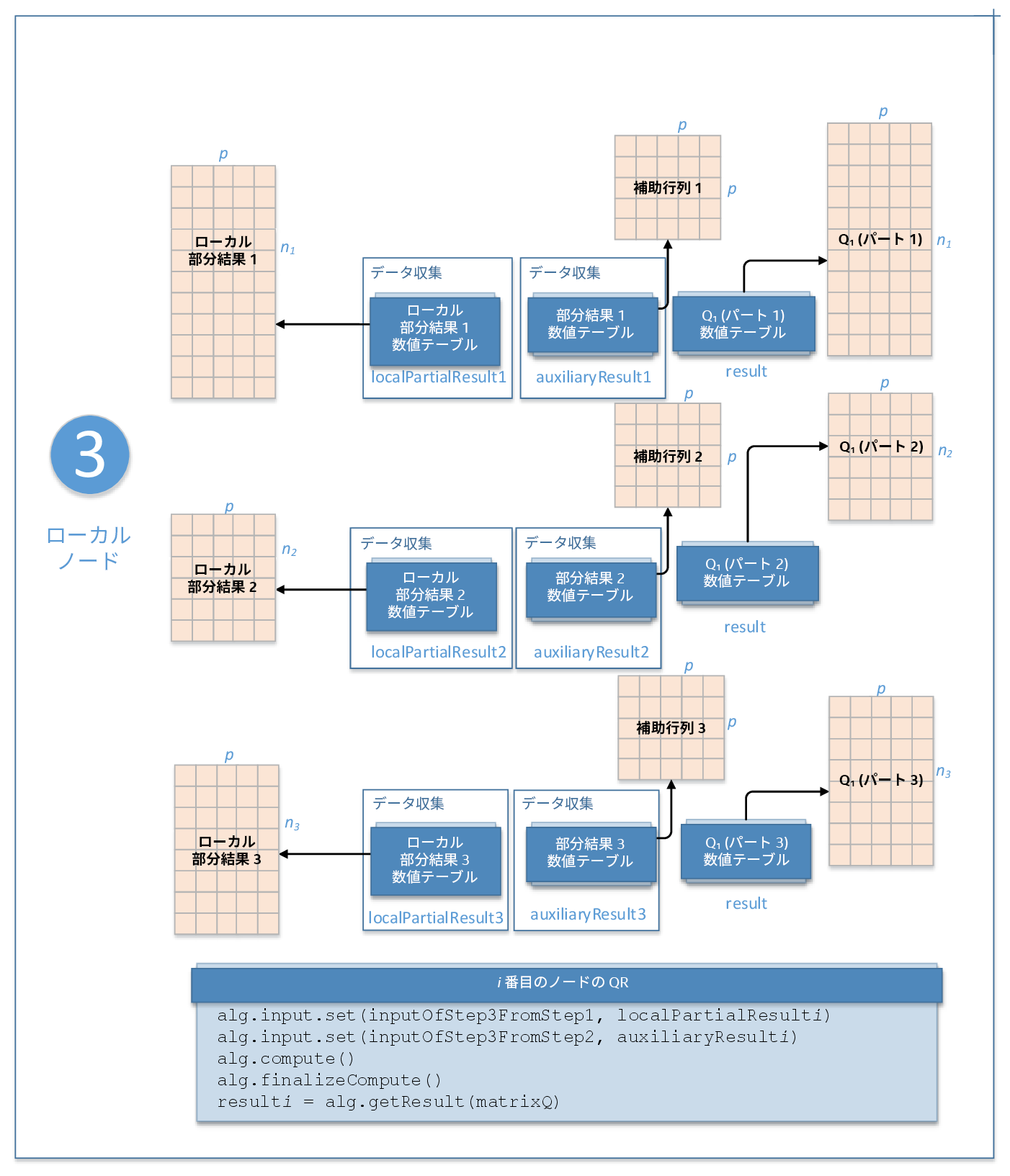
このステップの QR 分解の入力は次のとおりです。入力 ID をパラメーターとして、アルゴリズムの入力を提供するメソッドに渡します。詳細は、「アルゴリズム」を参照してください。
入力 ID |
入力 |
|
|---|---|---|
inputOfStep3FromStep1 |
ステップ 1 でローカルノードで計算された結果 (outputOfStep1ForStep3) を含むコレクション。(PackedSymmetricMatrix および PackedTriangularMatrix を除く) NumericTable の派生クラスのオブジェクトをコレクションに含めることができます。 |
|
inputOfStep3FromStep2 |
ステップ 2 でマスターノードで計算された結果 (outputOfStep2ForStep3) を含むコレクション。(PackedSymmetricMatrix クラスおよび lowerPackedTriangularMatrix レイアウトの PackedTriangularMatrix クラスを除く) NumericTable の派生クラスのオブジェクトをコレクションに含めることができます。 |
|
このステップで、QR 分解は次の結果を計算します。結果 ID をパラメーターとして、アルゴリズムの結果にアクセスするメソッドに渡します。詳細は、「アルゴリズム」を参照してください。
結果 ID |
結果 |
|
|---|---|---|
matrixQ |
n x p 行列 Q1 を含む数値テーブルのポインター。デフォルトでは、この結果は HomogenNumericTable クラスのオブジェクトですが、(PackedSymmetricMatrix、PackedTriangularMatrix、および CSRNumericTable を除く) NumericTable の派生クラスのオブジェクトとして定義できます。 |
|
サンプル
インテル® DAAL ディレクトリーの次のサンプルを参照してください。
C++: ./examples/cpp/source/qr/qr_distributed.cpp
Java*: ./examples/java/source/com/intel/daal/examples/qr/QRDistributed.java